Reducing memory usage in pandas with smaller datatypes
Optimizing pandas memory usage by the effective use of datatypes
The article was originally published here

Managing large datasets with pandas is a pretty common issue. Despite this, there are a few tricks and tips that can help us manage the memory issue with pandas to an extent. They might not offer the best solution, but the tricks can prove to be handy at times. Hence there is no harm in getting to know them. I talked about two such alternative ways of loading large datasets in pandas in one of my previous article.
These techniques are :
-
Chunking: subdividing datasets into smaller parts
-
Using SQL and pandas to read large data files
This article is a sort of continuation to the above techniques. Hence, if you haven’t read the previous article, it’ll be a good idea to do so now 😃. In this article, we’ll cover ways to optimize memory use by the effective use of datatypes. But first, let’s get to know the pandas’ datatypes in detail.
Pandas datatypes
A datatype refers to the way how data is stored in the memory. To be more succinct and quoting Wikipedia here:
a data type or simply type is an attribute of data that tells the compiler or interpreter how the programmer intends to use the data.
The primary data types consist of integers, floating-point numbers, booleans, and characters. Pandas’ also follows the same discourse. Here is a quick overview of various data types supported by pandas:
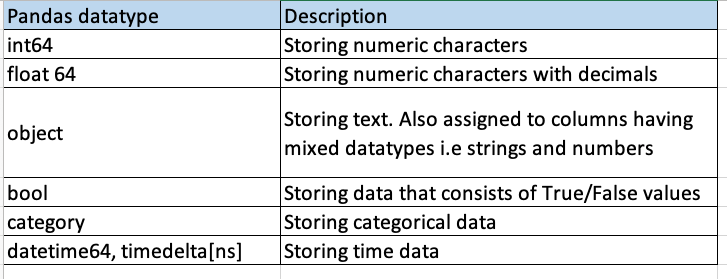
The int and float datatypes have further subtypes depending upon the number of bytes they use to represent data. Here is a complete list:
: r*eleased under the [MIT license](https://opensource.org/licenses/MIT).*](https://cdn-images-1.medium.com/max/2000/1*fsEpwfWQBMnaC6iISieHOw.png)
This is a long list but let’s touch upon few critical points:
-
The number preceding the name of the datatype refers to the number of bits of memory required to store a value. For instance, int8 uses 8 bits or 1 byte; int16 uses 16 bits or 2 bytes and so on.
-
The larger the range, the more memory it consumes. This implies that int16 uses twice the memory as int8 while int64 uses eight times the memory as int8.
-
uint8, uint16 etc. refer to unsigned integers while int refers to signed integers. There is no difference in the amount of memory allocated, but as the name suggests, unsigned integers can only store positive values, i.e., 0–255, for uint8. The same applies to uint16,uint32, and uint64 respectively.
The datatypes are important since the way data is stored decides what can be done with it.
Seeing things in action
Now that we have a good idea about pandas’ various data types and their representations, let’s look at ways to optimize storage when using them. I’ll be using a file comprising 1.6 GB of data summarising yellow taxi trip data for March 2016. We’ll start by importing the dataset in a pandas’ dataframe using the read_csv() function:
import pandas as pd
df = pd.read_csv('yellow_tripdata_2016-03.csv')
Let’s look at its first few columns:
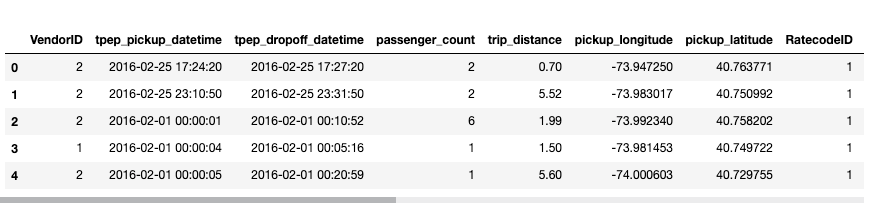
By default, when pandas loads any CSV file, it automatically detects the various datatypes. Now, this is a good thing, but here is the catch. If a column consists of all integers, it assigns the int64 dtype to that column by default. Similarly, if a column consists of float values, that column gets assigned float64 dtype.
df.info()
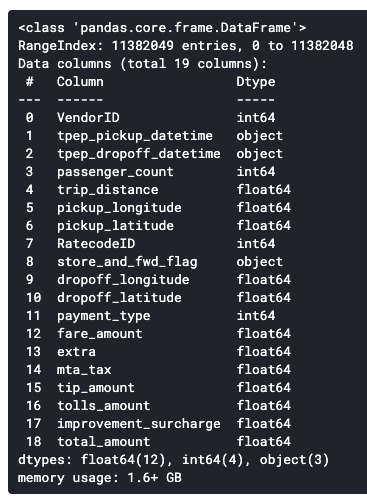
As stated above, three datatypes have been used in this case:
-
int64 for integers values,
-
float64 for float values and,
-
object datatype for datetime and categorical values
Numerical data
On inspecting our dataframe, we find that the maximum value for some of the columns will never be greater than 32767. n such cases, it is not prudent to use int64 as the datatype, and we can easily downcast it to say, int16. Let’s understand it more concretely through an example.
For the demonstration, let’s analyze the passenger count column and calculate its memory usage. we’ll use the pandas’ memory_usage() function for the purpose.
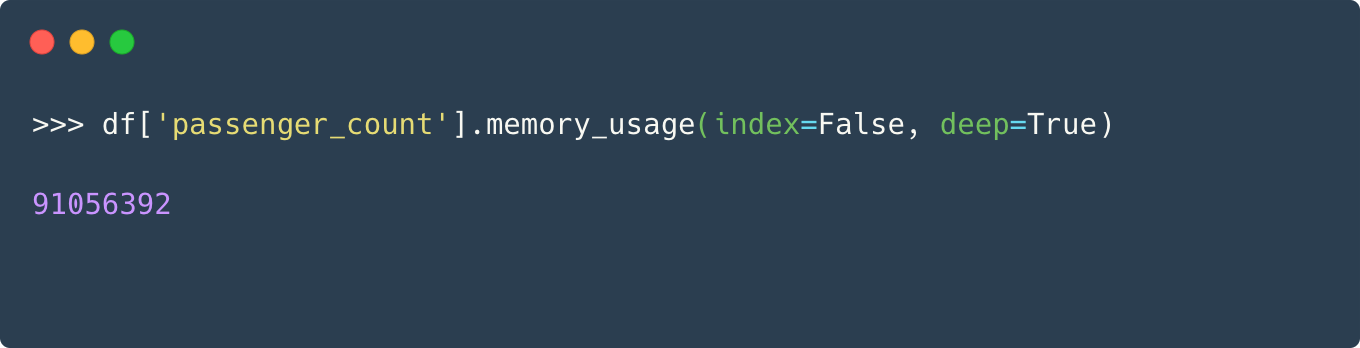
To understand whether a smaller datatype would suffice, let’s see the maximum and minimum values of this column.
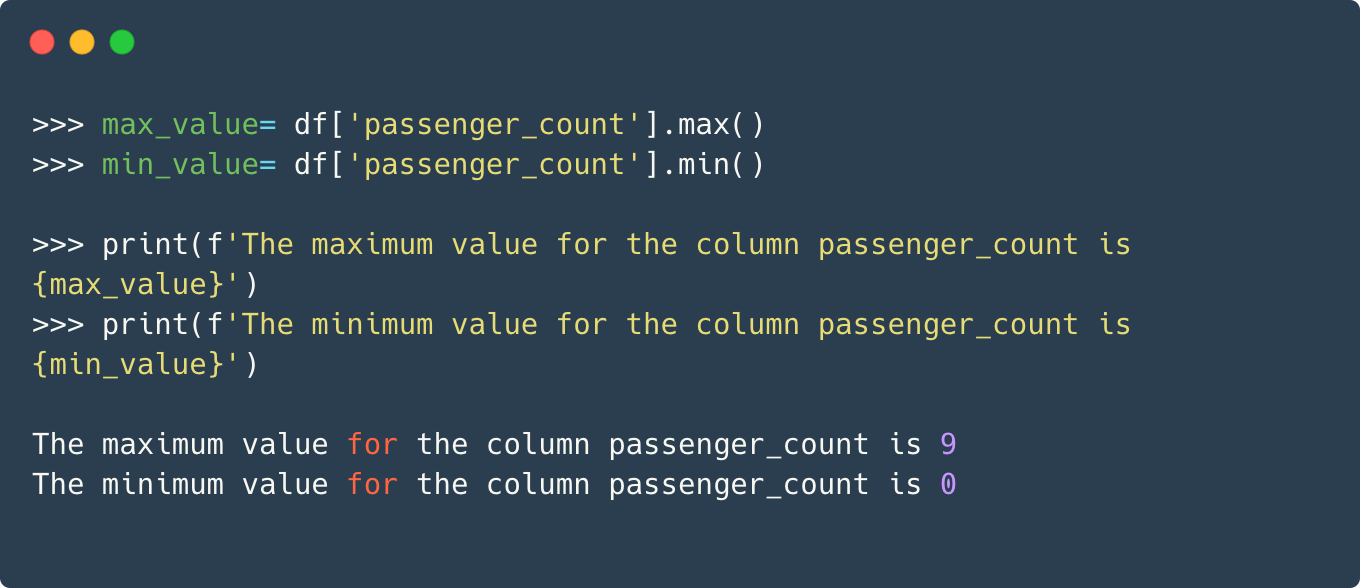
Since the column only consists of positive values with the max being only 9, we can easily downcast the datatype to int8 without losing any information.

That is a considerable decrease in the memory used. Let’s take another example. This time we shall analyze the pickup_longitude column, which consists of float values.
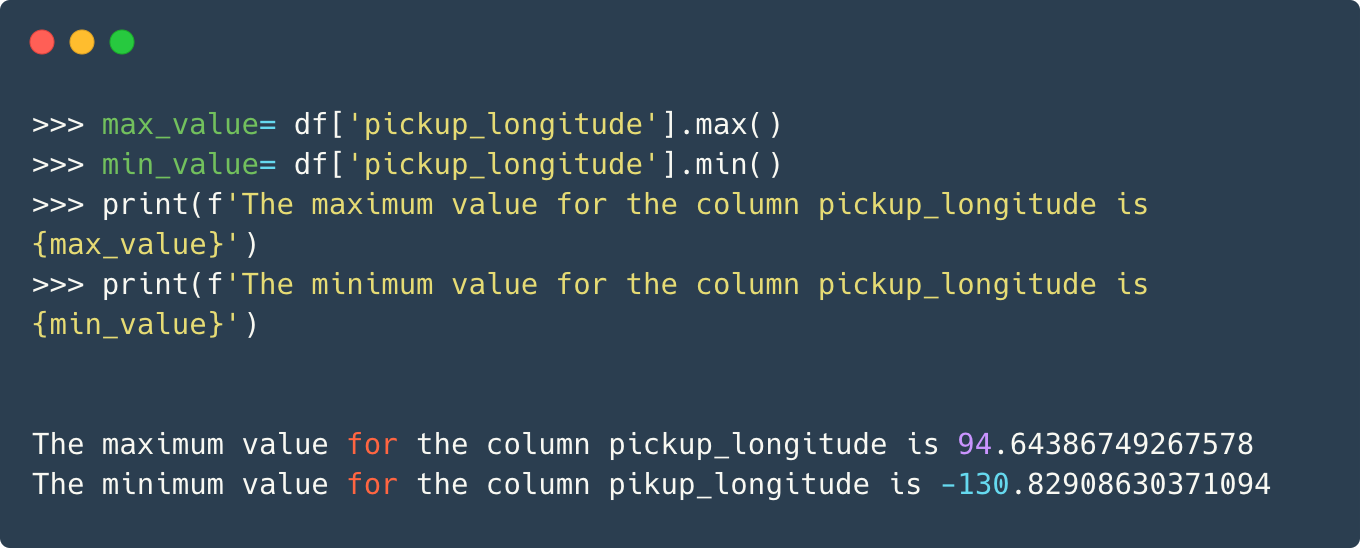
Now, you would agree that for the longitude(and latitude) column, values up to two decimal places would be decent in conveying the information. The advantage, on the other hand, in terms of reduction in memory usage would be immense. We can change the datatype from float64 to float16 and this would cut down the memory usage by 1/4th.
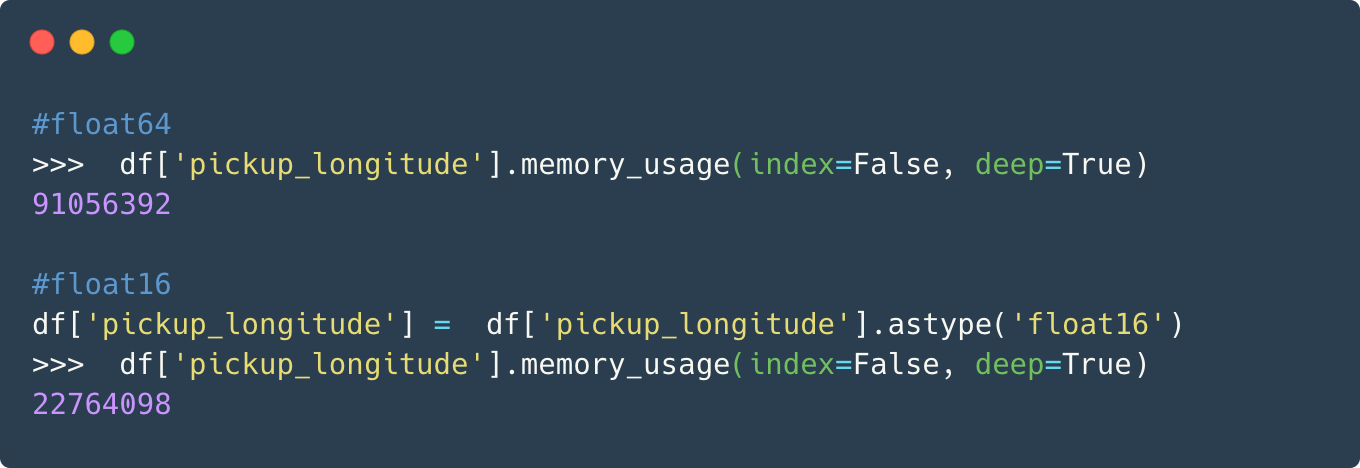
This is great. We can similarly downcast other columns by analyzing them and can save a considerable amount of memory.
Categorical data
Till now, we have looked at only the numerical columns. Is there a way to optimize categorical columns as well? Well, yes, there are ways to reduce the memory consumption of categorical columns as well. Let’s take the case of the **store_and_fwd_flag **column, and as shown in the previous section, calculate the memory required to store it.

The dtype ‘O’ refers to the object datatype. Now, if we’re to look at the unique values in this column, we would get:
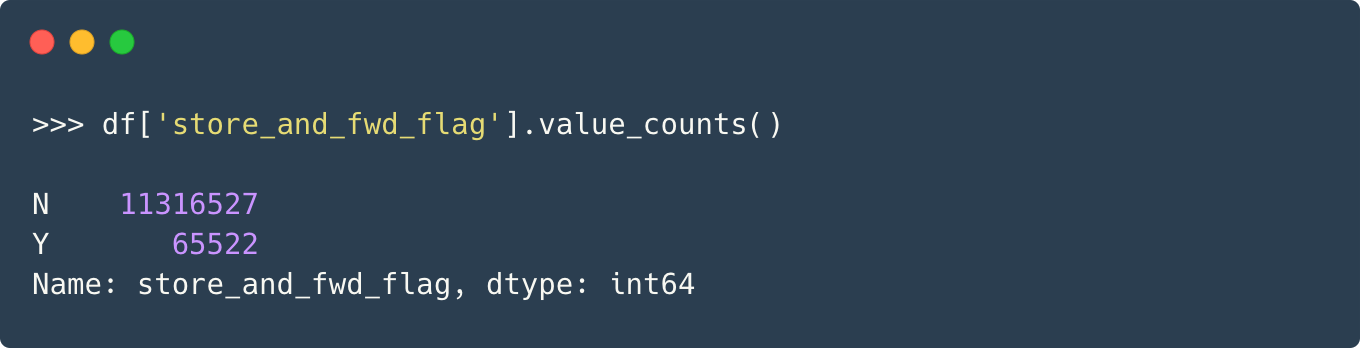
There are only two unique values, i.e., N and Y, which stand for No and Yes, respectively. In such cases where there are a limited number of values, we can use a more compact datatype called Categorical dtype. Here is an excerpt from the documentation itself:
Categoricals are a pandas data type corresponding to categorical variables in statistics. A categorical variable takes on a limited, and usually fixed, number of possible values (categories; levels in R). Examples are gender, social class, blood type, country affiliation, observation time or rating via Likert scales.
If we were to downcast the object type to categorical dtype, the decrease in memory usage would be as follows:

Again, a decent amount of memory reduction is achieved.
Finally, we can also specify the datatypes for different columns at the time of loading the CSV files. This could be useful for data that throws out of memory error on loading.

Conclusion
In this article, we saw how we could optimize the memory being used by the dataset. This is especially useful if we have limited RAM and our dataset doesn’t fit in the memory. However, it will be helpful to look at some other libraries that can handle the big data issue much more efficiently.